Abstract
Robots are expected to serve as intelligent assistants, helping humans with everyday household organization. A central challenge in this setting is the task of object placement, which requires reasoning about both semantic preferences (e.g., common-sense object relations) and geometric feasibility (e.g., collision avoidance). We present GOPLA, a hierarchical framework that learns generalizable object placement from augmented human demonstrations. A multi-modal large language model translates human instructions and visual inputs into structured plans that specify pairwise object relationships. These plans are then converted into 3D affordance maps with geometric common sense by a spatial mapper, while a diffusion-based planner generates placement poses guided by test-time costs, considering multi-plan distributions and collision avoidance. To overcome data scarcity, we introduce a scalable pipeline that expands human placement demonstrations into diverse synthetic training data. Extensive experiments show that our approach improves placement success rates by 30.04 percentage points over the runner-up, evaluated on positioning accuracy and physical plausibility, demonstrating strong generalization across a wide range of real-world robotic placement scenarios.
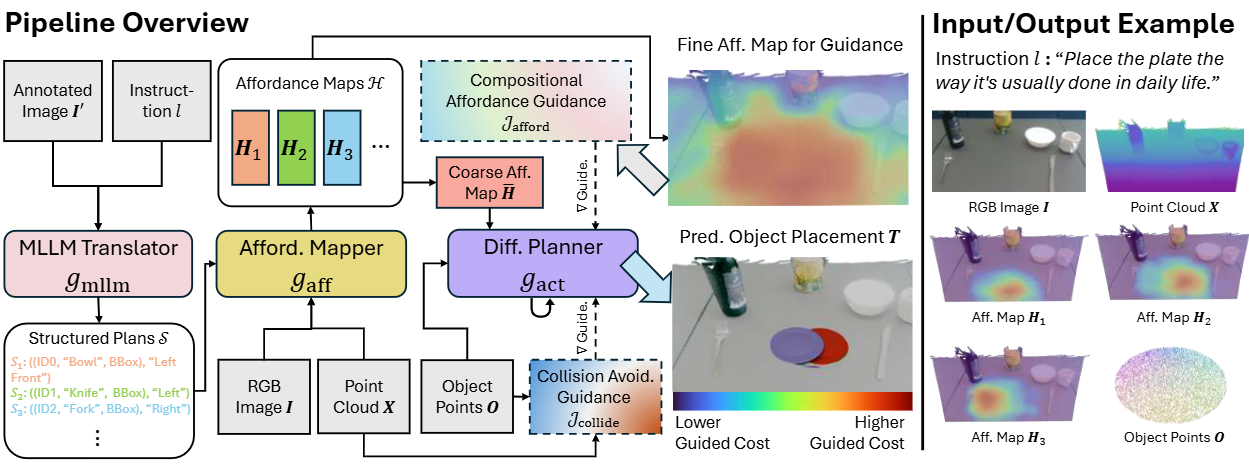
Fig 1: Overview of our proposed placement model. A hierarchical model is used to infer the pose of an object to be placed, capturing both the user preference and the physical plausibility.
Single Object Placement
Sequential Object Placement
Multi-modal Context
Video Presentation
BibTeX
@misc{zhong2025goplageneralizableobjectplacement,
title={GOPLA: Generalizable Object Placement Learning via Synthetic Augmentation of Human Arrangement},
author={Yao Zhong and Hanzhi Chen and Simon Schaefer and Anran Zhang and Stefan Leutenegger},
year={2025},
eprint={2510.14627},
archivePrefix={arXiv},
primaryClass={cs.RO},
url={https://arxiv.org/abs/2510.14627}
}